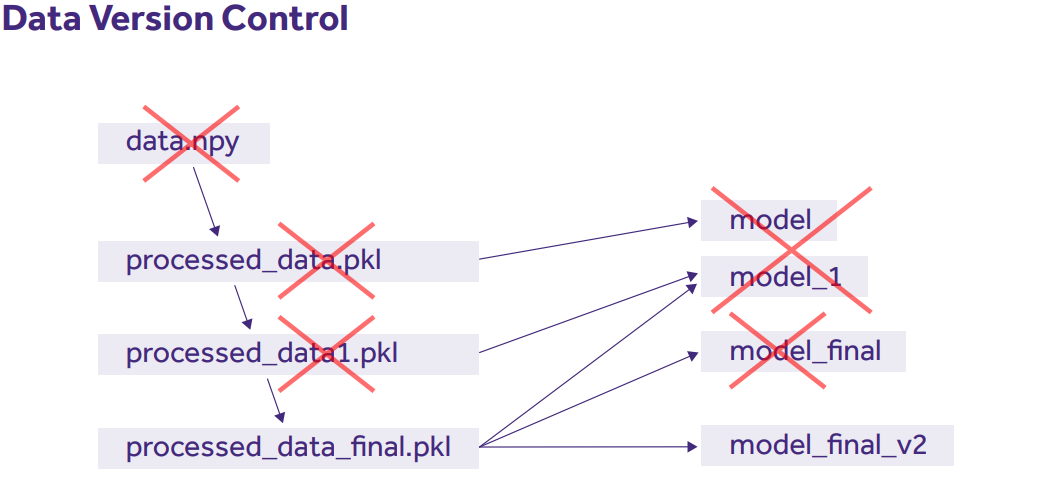
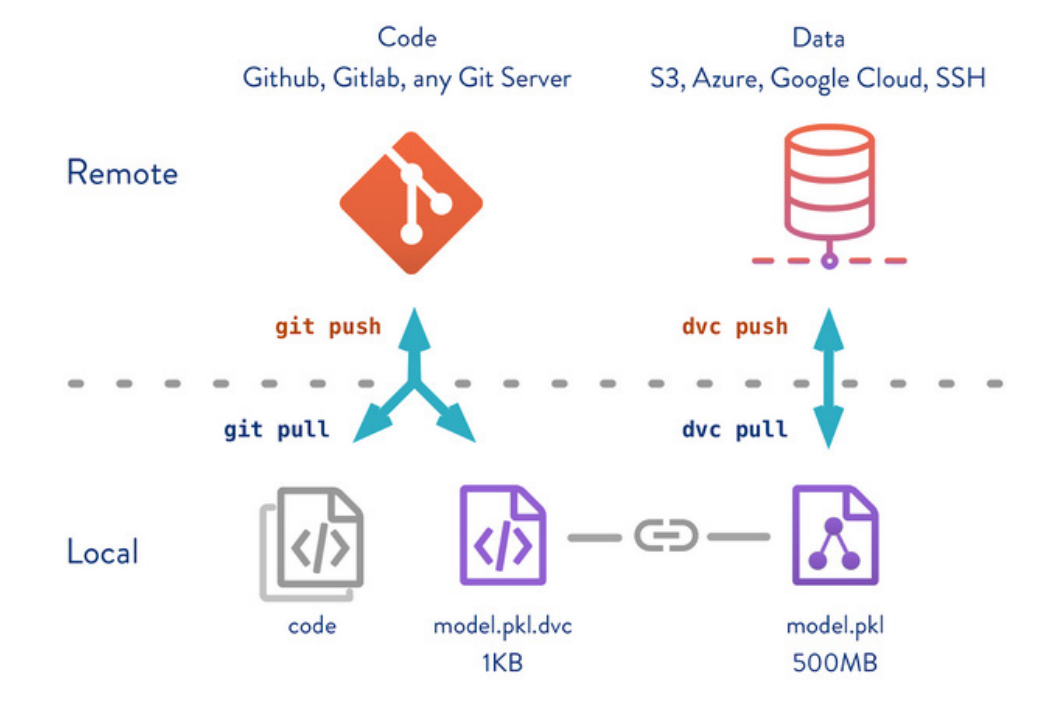
Core DVC features
– Git-compatible – DVC runs on top of any Git repository
– Storage agnostic – Amazon S3, Google Drive, Google Cloud Storage, SSH/SFTP, HTTP, local or network-attached storage, etc.
– Reproducible – the single ‘dvc repro’ command reproduces experiments end-to-end
– Low friction branching – DVC fully supports instantaneous Git branching, even with large les metric tracking – DVC includes a command to list all branches, along with metric values
– ML pipeline framework – DVC has a built-in way to connect ML steps into dependency graphs DAG (directed acyclic graph) language and framework-agnostic – Python, R, Julia, Scala Spark, Notebooks, atles/TensorFlow, PyTorch, etc.
– HDFS, Hive & Apache Spark – include Spark and Hive jobs in the DVC data versioning
– Track failures – retaining knowledge of failed attempts can save time in the future
Why DVC
There are several alternatives to the DVC (e.g. Git LFS, MLFlow, Pachyderm, Delta Lake, Neptune, lakeFS or Allegro Trains / ClearML). A number of them are more extensive and complete than others, while some lack certain functionalities. What distinguishes DVC from the crowd is its ease of use, similar functionalities to that of Git and the possibility of integration with ML pipelines as a part of an extensive system. It is denitely worth checking out!
Bibliography:
- Git description
- Data Version Control With Python and DVC
- Data version control with DVC. What do the authors have to say?