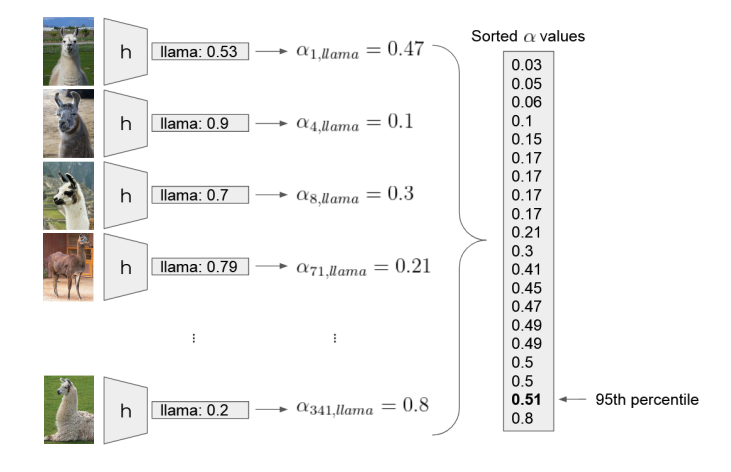
Calibration example of the “llama” label. Let’s assume there are 20 images with this label in the calibration set. We input each image 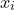 into the model
into the model 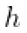 , fetch the softmax output for the “llama” class
, fetch the softmax output for the “llama” class 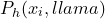 and compute the nonconformity score
and compute the nonconformity score 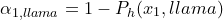 . We collect all the nonconformity scores and find the 95th percentile
. We collect all the nonconformity scores and find the 95th percentile 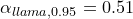 .
.
During inference, we input a new image . We iterate over all labels and exclude label L if nonconformity score is higher than threshold 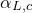 . Otherwise we keep the label. For example:
. Otherwise we keep the label. For example:
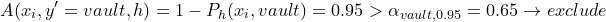
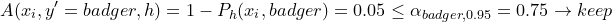
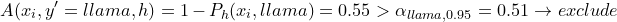
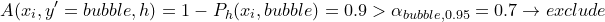
We might end up with a set of labels
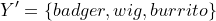
Again, how to interpret such a result? If our task is to state if there is a fish in the image, then we’re rather certain that it’s absent. But, if we would like to distinguish wigs from burritos, we can say that our model is not certain about that.
The procedure guarantees that

for each class separately – expected probability of the correct label being included in the output set is c.
Evaluation
The error level is defined by the user, so it cannot be used to measure the quality of predictions. Instead, we can look at the size of the output prediction set, e.g. the average number of output labels.
We can also measure efficiency. The algorithm is efficient when the output prediction set is relatively small and therefore informative. We can define efficiency as the number of predictions with only one label divided by the number of all predictions.
Yet another measure is called validity. We can define it as a fraction of the predictions with only one label that were predicted correctly.
Summary
This blog post sheds some light on how to apply Mondrian Conformal Prediction to a classification problem in the inductive setting. Key take-home messages:
- Conformal Prediction quantifies uncertainty of each prediction separately.
- It’s flexible – any predictive model can be applied.
- It outputs set-valued predictions instead of point estimates.
- It provides error rate guarantees.
References
Original book that introduced the method:
Vovk, Vladimir & Gammerman, Alex & Shafer, Glenn. (2005). Algorithmic Learning in a Random World.
This blog post relies on:
https://www.youtube.com/watch?v=eXU-64dwHmA



