This blog post highlights how large language models (LLMs) can serve as AI Assistants to automate metadata annotation, helping expert teams in the curation of biological databases. We present a case study demonstrating the application of LLMs in annotating the NCBI’s Gene Expression Omnibus (GEO) repository to showcase the utility of AI-assisted workflows on translational research and drug discovery.
Table of Contents:
- Advantages of LLMs for metadata annotation/a>
- Existing tools and frameworks/a>
- Case study: Using AI Assistant to integrate and annotate the NCBI’s Gene Expression Omnibus (GEO)
- The future of metadata annotation: LLM-based AI assistants for experts
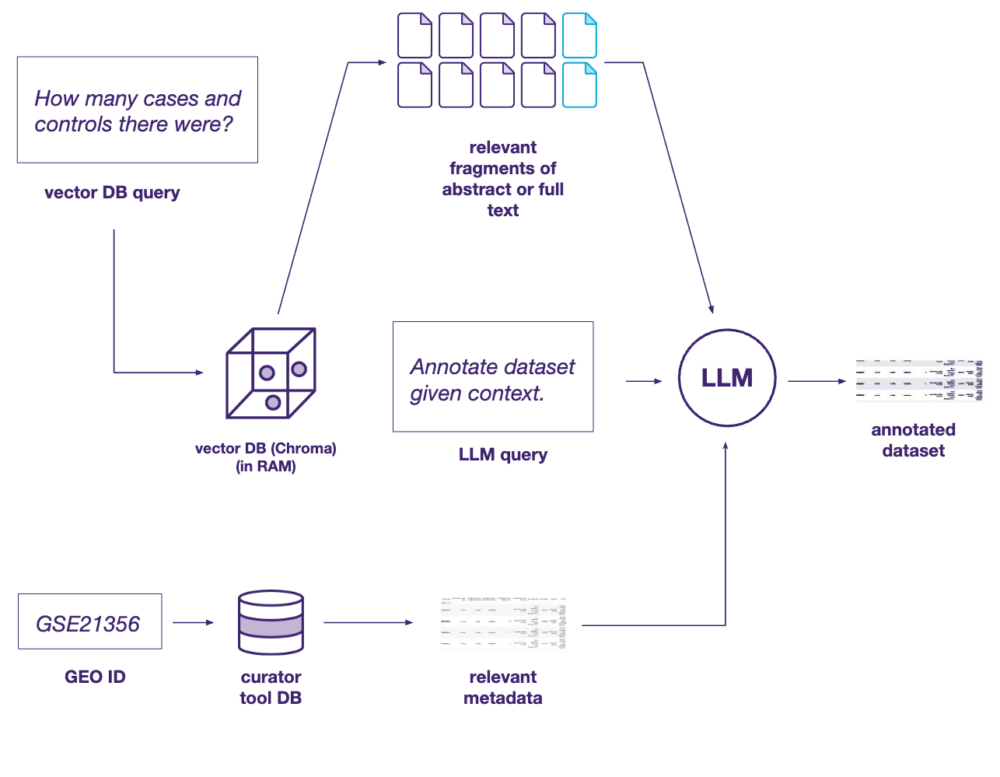
AI Assistant tailored for metadata annotation represents a valuable tool for collecting and unifying important context for the analysis of omics studies and other cohorts of bioinformatic datasets. This approach involves optimizing large language models (LLMs) and natural language processing (NLP) algorithms to categorize, organize and standardize biological datasets, helping improve the accuracy, completeness and usability of the datasets as well as speed up the annotation process by reducing the time-consuming and repetitive workload associated with the manual curation of such datasets.
Biological metadata often lacks standardization, making it difficult to compare across multiple studies since the proper knowledge exists within multiple inconsistent sources, predominantly of an unstructured nature such as publications, abstracts, supplementary data, etc. Metadata includes information such as the study’s purpose, experimental design, sample characteristics, protocols used, data processing methods and relevant ontologies or controlled vocabulary terms to describe the dataset. Traditionally, this type of data is annotated manually by expert curators. However, the speed of generating new genomic, transcriptomic and other clinically relevant datasets largely outpaced the capabilities of even the most proficient expert teams.
Utilizing AI assistants based on LLMs can significantly simplify and accelerate this process, allowing researchers to focus on the most important, scientifically relevant aspects of the data instead of repetitive and laborious work. Automation allows researchers to use the data more effectively, implement larger, aggregated datasets (such as ontologies, public data banks and atlases) and extract relevant insights to empower translational, early discovery and target identification research.