
Versioning data projects seems to be the least popular feature in machine learning (i.e. data science projects). Fortunately, more people and organizations are starting to version their data, which includes both data sets and trained models. In software engineering, we often versioned our code with Git, for example, but traditional version control systems that are used for regular software projects aren’t quite sufficient for machine learning, as they need to be able to track the data sets, along with the code itself and resulting models.
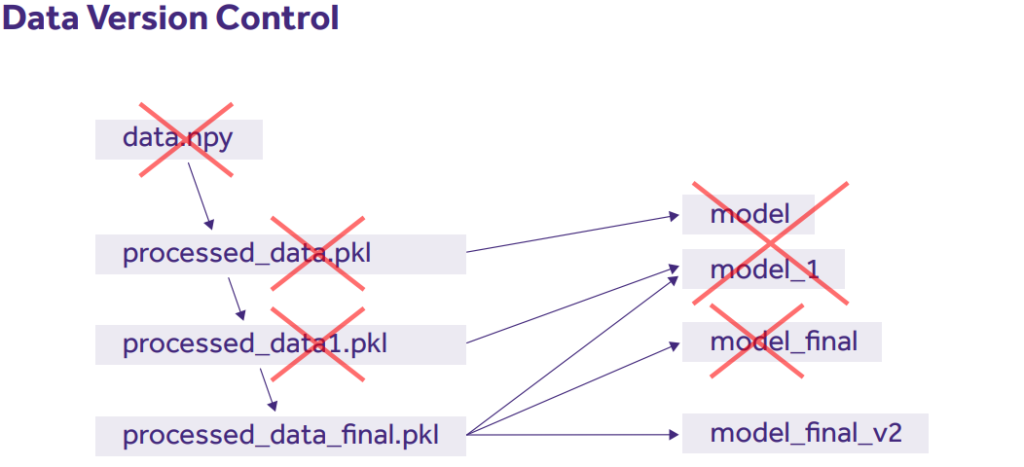
Figure 1.
Example of the structure of data sets and models without any data control system.
Let’s start from the version control system and for the purpose of this blog post, we will stick to Git. Git is software for tracking changes in any set of files, usually used for coordinating work among programmers collaboratively developing source code during software development1. In a nutshell, there’s a central code repository representing the current state of a project. We can copy the project, make some changes locally and push them to the central repository, and once the code is reviewed and accepted, it’s deployed to production. We’d like to see similar conventions and standards in data science and machine learning projects, but in this case, it’s not an obvious and popular procedure as it is in software development.
In machine learning, there are hundreds of experiments, and this is when problems may arise.
Data version control is a set of tools and processes that tries to adapt the version control process to the data world. Having systems in place that allow people to work quickly and pick up where others have left o would increase the speed and quality of delivered results. It would enable people to manage data transparently, run experiments effectively, and collaborate with others2.
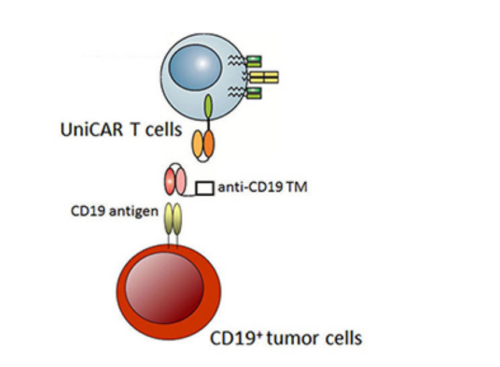 Figure 1. The concept of UniCAR-T cells.
Figure 1. The concept of UniCAR-T cells.
In the presence of target modules (TM) against the CD19 antigen, UniCAR-T cells are cross-linked to CD19+ tumor cells, which leads to their apoptosis. In the absence of the TM, UniCAR-T cells will automatically be switched off (Bachmann, et al; Retargeting of UniCAR T cells with an in vivo synthesized target module directed against CD19
positive tumor cells. Oncotarget.2018; 9: 7487-7500.
Retrieved from https://www.oncotarget.com/article/23556/text/
used under CC BY 3.0
 DVC stands for Data Version Control. It’s a command-line tool written in Python that helps data scientists manage, track and version data and models, as well as run reproducible experiments.
DVC stands for Data Version Control. It’s a command-line tool written in Python that helps data scientists manage, track and version data and models, as well as run reproducible experiments.
Basically, it’s a version control system for machine learning projects. You can think of DVC as a command line tool, it’s kind of Git for ML3.
It can track large data les (e.g. 10 GB data sets or ML models), version machine learning pipelines, organize and run experiments, make them self-descriptive and self-documented. Basically, we know how a model was produced, what kind of commands we need to run to reproduce the experiment and the kind of metrics that were produced as a result of this experiment.
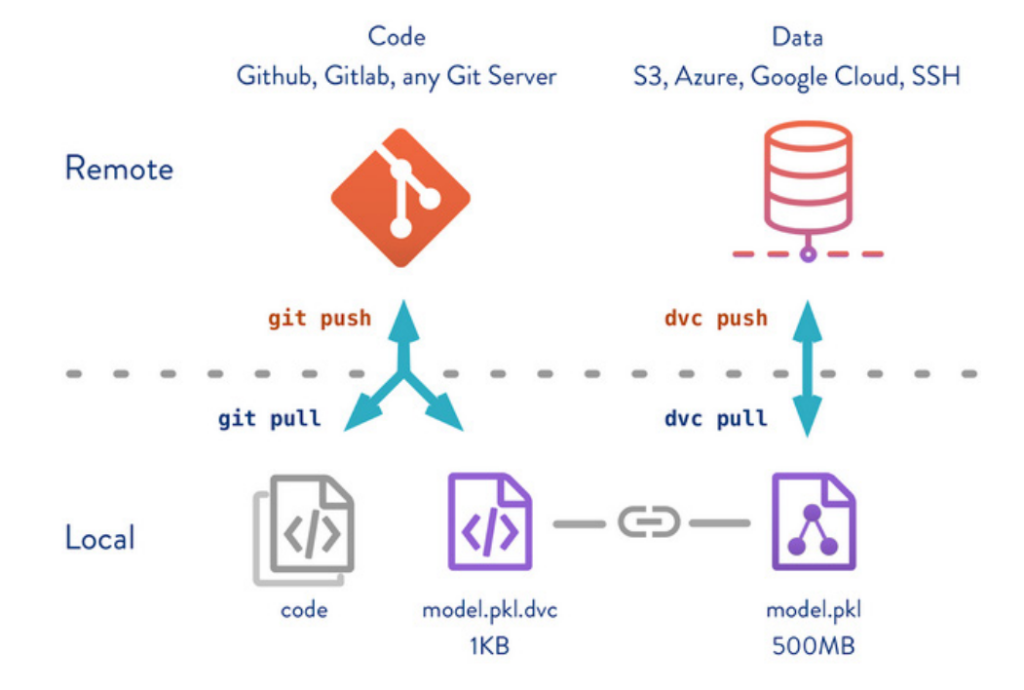
Figure 3.
Example structure of machine learning project using Git and DVC.



