
AI in Biotech: Lessons from 2025 and the Trends Shaping Drug Discovery in 2026
By the end of 2025, artificial intelligence had become a permanent element of biotechnology and pharmaceutical R&D. Not as a single breakthrough moment, but as a growing layer of tools influencing how hypotheses are generated, experiments are designed, and results are interpreted. At the same time, experience from across industries revealed a more sobering reality. A 2025 study by MIT found that nearly 95% of enterprise generative AI pilots failed to deliver measurable business impact, most often because systems remained disconnected from real workflows, data foundations, and organizational ownership.[1]
This tension defined much of the AI conversation in 2025. On the surface, adoption continued to accelerate. Beneath it, many initiatives stalled at the pilot stage, exposing gaps not in model capability, but in data readiness, integration, and governance. As a result, discussions began to shift away from isolated model performance toward system-level questions: how AI is embedded into discovery pipelines, how its outputs are validated, and how it fits within regulatory and operational constraints.
Understanding this shift is essential for interpreting the trends shaping 2026. The next phase of AI in biotech will be defined less by new algorithms and more by whether organizations can move from experimentation to dependable infrastructure.

Fig 1 AI adoption in biotech has progressed from isolated experiments to integrated, production-ready systems shaped by regulation, data maturity, and platform thinking.
2025: when AI became part of the operating model
Market forecasts remained strong throughout 2025. Precedence Research projects continued double-digit growth of artificial intelligence in biotechnology globally, with estimates pointing to a market exceeding USD 25 billion by the mid-2030s. For a more concrete reference point, the same analysis places the U.S. market at approximately USD 2.1 billion in 2025, with growth driven primarily by adoption in drug discovery, genomics, and precision medicine.[2,3]
Inside organizations, the biggest shift was how AI was treated. Once models are connected to data pipelines, lab workflows, or decision-support tooling, they behave like infrastructure: they need monitoring, versioning, clear ownership, and change control. Many teams found that the hard part starts after deployment, when data drift, integration debt, and maintenance become recurring costs.
This changed investment priorities. More effort moved into data engineering, workflow automation, and system integration. “AI maturity” started to look less like a model leaderboard and more like whether a team can keep systems stable, auditable, and useful across programs.
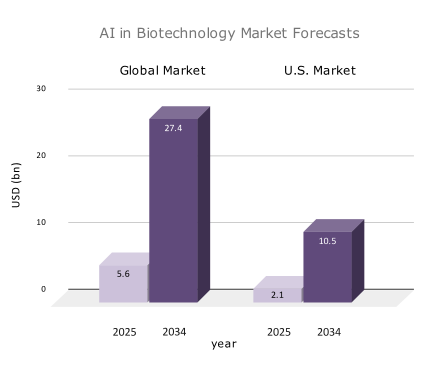
Fig 2 Market growth projections for artificial intelligence in biotechnology. Global estimates indicate sustained expansion through the mid-2030s, while U.S. market data provide a concrete reference point for adoption across drug discovery, genomics, and precision medicine.
AI moves closer to regulatory decisions (and the evidence behind them)
A defining development of 2025 was AI’s increasing proximity to decisions with regulatory implications, especially when AI is used to generate information intended to support assessments of safety, effectiveness, or quality. In January 2025, the FDA published draft guidance outlining a risk-based credibility assessment framework for AI models used in this context, emphasizing “context of use” and ongoing performance evaluation. [4]
It is important to describe that scope precisely. The guidance focuses on AI used to produce information or data that supports regulatory decision-making across phases of the product lifecycle; it is not a general endorsement of using AI everywhere in R&D, and commentary on the document notes it does not cover AI used in drug discovery or operational efficiencies that do not affect patient safety, product quality, or study reliability. For discovery teams, the practical takeaway is still relevant: if AI outputs could later influence regulated claims or submissions, traceability and validation are easier to build early than retrofit later.
In parallel, the FDA publicly outlined plans to reduce, refine, or potentially replace certain animal testing requirements and to promote new approach methodologies (NAMs) in appropriate contexts, including organoids, organ-on-chip systems, and computational models [5]. While these initiatives are often discussed separately, their convergence points toward a broader shift in how biological evidence is generated and interpreted.
One emerging concept in this space is the idea of the digital cell or, more broadly, digital representations of biological systems. Rather than relying on single experimental readouts, digital cell models integrate multimodal data—from omics and imaging to perturbation experiments—to simulate cellular behavior under different conditions. In this framing, AI does not replace experimental systems but acts as a connective layer that links in vitro data, computational models, and biological interpretation. [6]
This approach aligns closely with the regulatory direction signaled by the FDA. As new approach methodologies mature, their value increasingly depends on the ability to contextualize results, quantify uncertainty, and relate model outputs to real biological mechanisms. Digital cell models offer a way to aggregate evidence across experimental systems, making it easier to reason about mechanism, predict response, and identify risk earlier in development.
Importantly, this is not a near-term replacement for established safety paradigms. Instead, it reflects a gradual rebalancing, where AI-supported, human-relevant models complement traditional approaches and help narrow experimental focus. Over time, such systems may enable more targeted experimentation, reduce late-stage attrition, and support regulatory confidence by providing structured, reproducible evidence rather than isolated results.[7]
Data maturity outweighs data volume
Large-scale datasets kept expanding in 2025, but many teams saw diminishing returns when scaling AI by volume alone. The recurring blockers were familiar: inconsistent annotations, missing metadata, weak provenance, and difficulties aligning datasets collected for different purposes. In multimodal settings, the gap between “we have multiple data types” and “they line up cleanly enough to learn from” was often the decisive factor.
That reality pushed data governance and integration higher up the priority list. Teams that invested in standardized schemas, controlled vocabularies, and data lineage made it easier to reuse models, compare experiments, and extend work across programs. What mattered most was data depth: biological context plus technical consistency.
This distinction becomes clear in recent multimodal AI applications. For example, studies combining transcriptomics with high-content imaging show that model performance improves not merely by adding modalities, but by explicitly aligning perturbation conditions, cell states, and experimental metadata across data types. When gene expression profiles are interpreted alongside phenotypic imaging features under the same experimental context, models can better distinguish mechanism-driven effects from noise and batch artefacts. In such cases, the value of multimodal AI comes from integration quality and biological alignment, not from the number of modalities alone [8].
Platforms and long-term partnerships reshape discovery pipelines
2025 also reinforced the move toward platform-oriented strategies. Large pharma companies increasingly pursued longer-term approaches that integrate data, models, and workflows rather than deploying single task tools. A clear example is Eli Lilly’s TuneLab, positioned as a platform providing biotech partners access to AI/ML models built on extensive proprietary datasets. [9]
At the same time, similar thinking is emerging outside traditional pharma structures. Ginkgo Bioworks, for instance, introduced Datapoints — curated biological datasets explicitly designed for pretraining and fine-tuning AI models. Rather than offering a closed platform, Datapoints treats high-quality, well-annotated biological data as a reusable product that can be shared across organizations and use cases. This approach highlights an important shift: in platform strategies, durable value increasingly comes not only from models themselves, but from how biological data is structured, contextualized, and made reusable for downstream AI applications [10].
Similarly, multi-year collaborations focused on AI-enabled molecular design continued to expand, such as Takeda’s expanded partnership with Nabla Bio around an AI platform for protein-based therapeutic design.[11] The common theme is not that “AI replaces R&D,” but that organizations are building reusable infrastructure where insights and models can compound across programs.
2026: trends shaping the next phase
Generative AI becomes embedded in daily work. Deloitte’s 2026 Life Sciences Outlook highlights accelerated digital transformation (48% of respondents) and identifies generative AI as an influential trend (41%), reflecting how analytics and automation are expected to shape research and operations. [12] Teams seeing real gains tend to integrate generative tools into defined workflows and couple them with governance around sources, validation, and traceability.
Autonomy advances, oversight remains essential. More agent-like systems will appear in R&D, but the operational requirement will be auditability and clear human accountability. The regulatory direction in the U.S. and EU continues to emphasize transparency, documentation, and lifecycle controls for AI in regulated contexts.[4]
Governance becomes a design constraint. The EU AI Act applies progressively, and the European Commission’s timeline specifies key milestones, including obligations for general-purpose AI models applying from 2 August 2025 and a staged roll-out through 2027. [13] For life sciences teams, this has architectural consequences: logging, risk management, and traceability cannot be bolted on at the end.
What this means for drug discovery teams
Success in 2026 will depend on systems thinking. Teams need strong data foundations, clear validation practices, and collaboration across biology, engineering, and quality functions. AI impact will hinge less on isolated technical advances and more on whether models sit inside dependable workflows that remain interpretable to scientists and defensible to stakeholders.
Scaling AI also means scaling governance and communication. Organizations that treat documentation, monitoring, and accountability as core capabilities are more likely to build cumulative value across programs rather than restarting with each new initiative.
Ardigen’s perspective
Across projects, the limiting factor is rarely access to algorithms. It is the ability to transform heterogeneous biological data into systems that produce reliable, interpretable insight over time. Integration, quality control, and reproducibility often decide whether an AI component becomes an enduring capability or stays a one-off success.
Looking toward 2026, the initiatives most likely to deliver lasting value are those designed with production and validation in mind from the outset. Clear definitions of intended use, thoughtful multimodal integration, and architectures that support monitoring over time determine whether AI becomes part of discovery infrastructure rather than an experimental add-on.
If you would like to discuss these observations further, or explore how they relate to your own challenges and priorities for 2026, we would be glad to continue the conversation.
Bibliography
- MIT The GenAI Divide STATE OF AI IN BUSINESS 2025 https://mlq.ai/media/quarterly_decks/v0.1_State_of_AI_in_Business_2025_Report.pdf
- Precedence Research (Global): AI in Biotechnology Market
- AI in Pharma and Biotech: Market Trends 2025 and Beyond
- FDA: Considerations for the Use of Artificial Intelligence To Support Regulatory Decision
- FDA Announces Plan to Phase Out Animal Testing Requirement for Monoclonal Antibodies and Other Drugs
- Ma, C., Zhang, H., Rao, Y. et al. AI-driven virtual cell models in preclinical research: technical pathways, validation mechanisms, and clinical translation potential. npj Digit. Med. (2025). https://doi.org/10.1038/s41746-025-02198-6
- Leann Lac, Carson K. Leung, Pingzhao Hu, Computational frameworks integrating deep learning and statistical models in mining multimodal omics data, Journal of Biomedical Informatics, 152, 2024, https://doi.org/10.1016/j.jbi.2024.104629.
- Bhushan, A., Misra, P. Unlocking the potential: multimodal AI in biotechnology and digital medicine—economic impact and ethical challenges. npj Digit. Med. 8, 619 (2025). https://doi.org/10.1038/s41746-025-01992-6
- Reuters: Lilly launches TuneLab https://www.reuters.com/business/healthcare-pharmaceuticals/lilly-launches-ai-powered-platform-accelerate-drug-discovery-2025-09-09
- Ginkgo Bioworks. Datapoints: High-quality biological datasets for AI pretraining. https://datapoints.ginkgo.bio/datapoints-way
- Reuters: Nabla Bio & Takeda expand AI partnership https://www.reuters.com/business/healthcare-pharmaceuticals/us-biotech-nabla-bio-japans-takeda-expand-ai-drug-design-partnership-2025-10-14
- Deloitte Insights: 2026 Life Sciences Executive Outlook https://www.deloitte.com/us/en/insights/industry/health-care/life-sciences-and-health-care-industry-outlooks/2026-life-sciences-executive-outlook.html
- European Commission: EU AI Act implementation timeline https://ai-act-service-desk.ec.europa.eu/en/ai-act/timeline/timeline-implementation-eu-ai-act



