About the Case Study
In the rapidly evolving field of bioinformatics, managing and integrating vast amounts of public omics data is a significant challenge. To address this, a techbio company asked Ardigen to developed a tailored AI-powered metadata annotation pipeline designed to automate the extraction of structured insights from unstructured datasets. The solution pulls data from sources like NCBI GEO and PubMed, identifying and organizing key metadata fields essential for downstream analysis, machine learning applications, and comprehensive insight generation. By leveraging Large Language Models (LLMs), Retrieval Augmented Generation (RAG), and advanced AI techniques, this approach significantly reduces manual effort, enhances accuracy, and enables scalable data processing.
Goal
The primary objective was to build and integrate an optimized AI assistant for metadata annotation, improving efficiency, accuracy, and standardization across large-scale omics datasets.
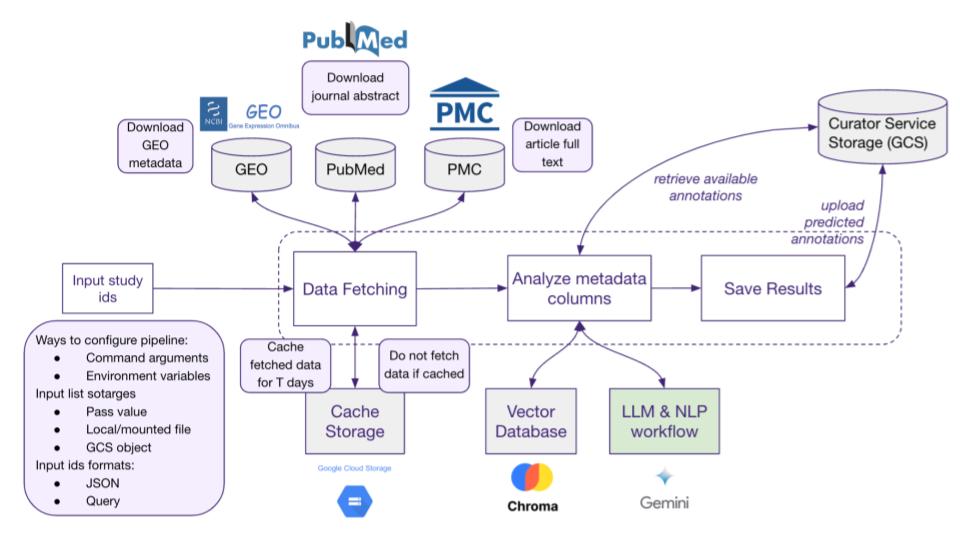
Approach
- Systematic validation with fine-tuning and testing
- LLM-based metadata extraction with optimized prompts
- Retrieval Augmented Generation (RAG) for enhanced data retrieval
- Normalization, ontology mapping, and AI-driven standardization
Results & Value:
- Drastically reduced annotation time from ~3 hours to just 5 minutes
- Expert-assessed accuracy exceeding 80%
- Fully integrated and deployed within the client’s cloud environment
This AI-driven solution revolutionizes metadata processing, enabling faster, more reliable, and scalable integration of public omics data, ultimately accelerating research and discovery.
Expert Contribution
Reviewed by: Dr. Piotr Faba, PhD
Role: Director of Software Engineering, AI‑Driven Drug Discovery
Expertise: Data integration, MLOps, cloud-native AI solutions, advanced analytics, life sciences data management



