
The NCBI’s Gene Expression Omnibus (GEO) is a public repository that archives and freely distributes microarray, next-generation sequencing, and other forms of high-throughput omics data submitted by the research community. There are a total of 35,000 clinically relevant human gene expression studies available in GEO. However, a major limitation to leveraging the full richness of GEO is the lack of standardized, consistent annotation that would make this dataset searchable and usable across studies. Annotations such as experimental conditions and sample types are essential for ensuring reproducibility, facilitating accurate analysis and integrating data from multiple sources to derive replicable, highly confident predictions. However, important features of the experiments are often hidden within paragraphs of accompanying scientific publications.
At Ardigen, we built an LLM tool to automate the annotation process for GEO. This tool was based on enterprise-grade LLMs such as GPT-4 or Gemini, implemented within a Retrieval-Augmented Generation (RAG) framework and supported by an underlying vector database. We used it to automatically annotate key fields in GEO studies, such as tissue, condition, drug and intervention, demonstrating its utility.
The annotation was verified by human experts in biology and evaluated over a pre-existing curated dataset of a few hundred studies. The LLM annotator was able to annotate datasets automatically with good accuracy, annotating dozens of datasets in minutes.
This project, like many of Ardigen’s cutting-edge AI initiatives, benefits from the insights of leaders such as Dawid Rymarczyk, PhD, Director of AI Solutions & Tribe Leader. Dr. Rymarczyk, a key organizer of the CVPR 2025 Workshop on Computer Vision for Drug Discovery, brings extensive expertise in deep learning and image analysis, ensuring our AI solutions for life sciences remain at the forefront of innovation.
Figure 1: Technical overview of the pipeline
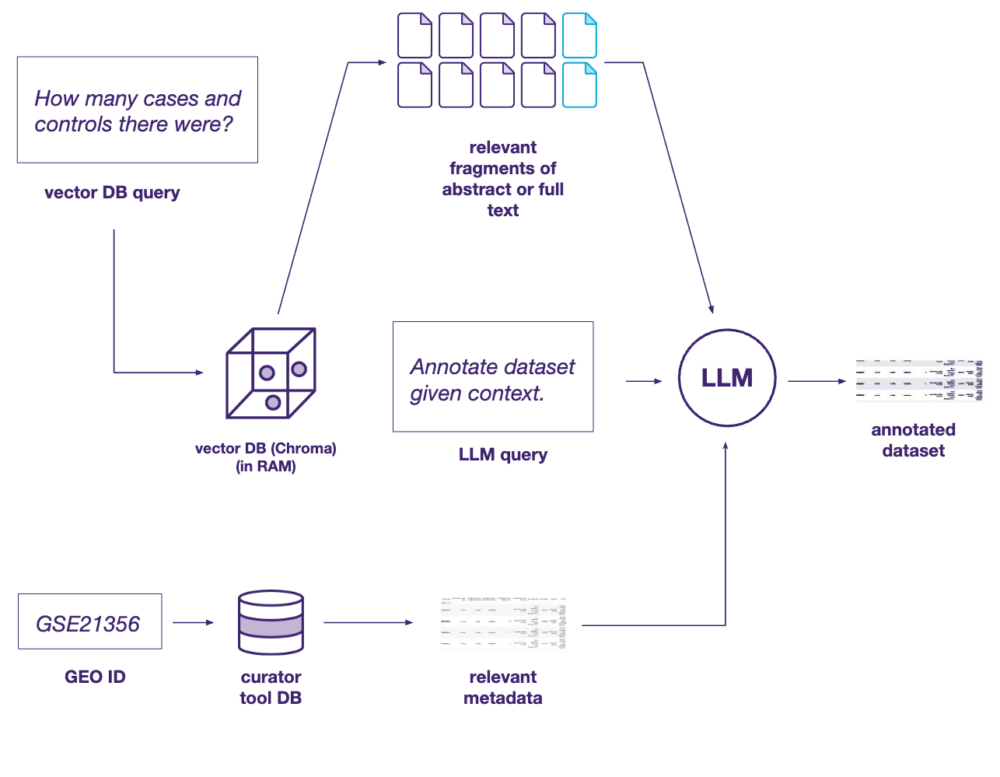
To maximize practical value, we connected the AI tool with existing annotation pipelines and internal processes of the Annotator Team, including live Connectors and APIs to facilitate data sharing between the client’s existing services. This solution was fully integrated and deployed within the client’s cloud environment (Figure 1). Ultimately, a cascade of various AI models was used to improve the efficiency and performance of the workflow, decreasing the time needed for primary annotation of a single study from 3 hours to 5 minutes (a 20-fold improvement). The expert-assessed accuracy of the solution exceeded 80% on average (Table 1).
The implementation of this custom LLM annotator delivered a significant boost to the productivity and scale of the client’s Annotator Experts Team. It now enables the team to process and standardize tens of thousands studies, which is critical for their drug discovery research.



