
Abstract
Understanding microbial proteins is essential to reveal the clinical potential of the microbiome as a whole. The application of novel high-throughput sequencing technologies allows for the fast and inexpensive acquisition of all potential protein sequences from a microbial community. However, many of these sequences do not resemble those of previously characterized proteins. Therefore, predicting their function through conventional alignment-based approaches is challenging. Recent research has shown that deep learning – a collection of prominent Artificial Intelligence methods – may be the missing piece in solving this problem. This is the first part of the series, which aims to advocate for the use of deep learning in metagenomics and will be soon followed by part two – a brief review of recent advances in deep learning-based protein function prediction.Introduction
The human gut is colonized by millions of commensal microorganisms, which makes it one of the most diverse ecosystems known. The gut microbiome is called the new “hidden” human organ due to the vast genetic potential of these organisms as well as their metabolic and biosynthetic capabilities. A growing body of evidence links the gut’s dysbiosis with diseases like diabetes, inflammatory bowel disease, cancer, or even autism, showing the microbiome’s profound impact on human health. However, we still lack a detailed understanding of these communities and mechanistic explanations of their role in developing diseases [1] [2]. Taxonomic profiling through 16S rRNA sequencing is possibly the most prevalent method for characterizing the human gut microbiota. By providing gut community microorganism composition, these studies have revealed unexpected correlations between bacteria and the host’s health. However, unrelated bacterial families can maintain analogous metabolic activities, making it difficult to infer functional mechanisms underneath phylogenetic associations. For this reason, the field is currently shifting its focus to the functional profiling of human microflora [1, 2]. Nevertheless, functional profiling is more challenging, as it requires the use of whole-genome sequencing (WGS) to sequence hundreds of thousands of genes from all microorganisms in a given sample. Genes encode proteins which each implement a biological function. The issue is that we are unable to deduce the function of more than 50% of all microbial proteins’ sequences. Despite remarkable progress in the last few decades, developing precise methods for functional prediction is still a major challenge in bioinformatics (see CAFA [3] and CASP [4] initiatives). The volume of metagenomic data is making the problem even harder. A powerful in silico method for predicting protein functions will have enormous benefits, not only for metagenomics.Predicting protein functions
The function of a protein is a direct derivative of its amino acid sequence. Currently, the general procedure for identifying a protein’s function is to compare a sequence of a novel protein to all experimentally examined sequences stored in multiple databases. BLAST [5] is the most popular tool for performing elemental sequence alignments. More advanced tools (e.g., PSI-BLAST [6], HMMER [7], HH-suite [8]) leverage multiple alignments to build models that find sequence patterns, such as profiles or motifs, and represent them as Position Weight Matrices (PWM) or Hidden Markov Models (HMM). These profiles can then be utilized to search databases iteratively to detect distant homologies, enabling the discovery of protein clusters or families that are evolutionarily connected. The alignment scores can help indicate the degree of sequence similarity between the novel sequence and existing database sequences. The above described approaches are both popular and powerful for protein function annotation directly from a protein sequence. However, these approaches are still limited in classifying sequences of proteins with similar function or structure, but distant in the sequence space. To illustrate, Cas9 and Cpf1 are both Class II CRISPR effector proteins with very similar functions, but they have very different domain architecture and share only ~15% amino acid identity. Existing approaches fail to reveal their analogous functions just by comparing their amino acid sequences [9]. Furthermore, nearly every novel metagenomic dataset contains new proteins with unique sequences. Despite the massive growth of databases in recent years, rich microbial diversity and rapid evolution make it impossible to catalog all proteins existing in nature. Moreover, current methods may not be able to handle such a volume of data. Therefore, we should shift our approach from comparing proteins to enormous databases to developing tools that can learn from these databases and draw functional conclusions.Deep learning
Deep learning is a proven technique to solve intricate problems and has been shown to work exceptionally well for tasks such as speech recognition, natural language processing (NLP), and image classification. Recently, it has been successfully utilized to analyze biological sequences like genomes or proteomes [10]. The most well-known example is DeepMind’s AlphaFold model [11, 12], which dominated the last protein structure prediction challenge – CASP13 [13]. However, there are many other related domains where deep learning is quietly becoming a standard, such as the prediction of transcription factor binding [14], de novo drug design [14], and base calling in nanopore sequencing [15]. The main reason for the tremendous success of deep neural networks in these fields is their ability to process massive amounts of data, even unlabeled, and learning meaningful patterns within them. Deep learning can handle, and even leverage, the exponential growth of data available in biological databases, which is a challenge in traditional methods. In (meta)proteomics, the ability of deep neural networks to learn from unlabeled data is particularly valuable, as the gap between the number of unlabeled and labeled proteins is widening every year [Figure 1].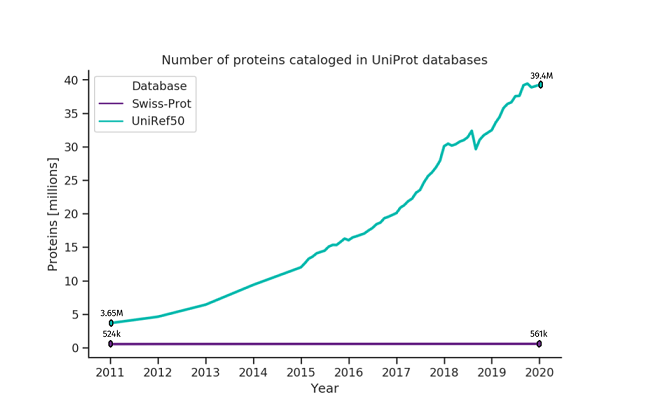 Figure 1. The number of proteins cataloged in UniProt databases [16]. Swiss-Prot contains reviewed and manually-annotated proteins. Its growth is unnoticeable compared to UniRef50 that comprises unreviewed, automatically annotated sequences.
Figure 1. The number of proteins cataloged in UniProt databases [16]. Swiss-Prot contains reviewed and manually-annotated proteins. Its growth is unnoticeable compared to UniRef50 that comprises unreviewed, automatically annotated sequences.
Summary
- Understanding of microbial proteins is crucial for unlocking the microbiome’s clinical potential.
- Developing a precise protein function prediction method is still a significant challenge.
- Deep learning is a powerful tool that, with sufficient amounts of data, can take proteomics far further than current methods.



