
Understanding Data in AI Drug Discovery: The Difference Between Having Any Data and Usable Data (part 1)
Summary:
- Why does AI fail in drug discovery despite massive datasets? AI in drug discovery does not fail because of weak algorithms, but because of poorly structured and unmanaged data.
- Having large datasets alone is insufficient. Data must be standardized, well-annotated, and designed for reuse to support reliable AI-driven decisions.
- 95% of AI initiatives fail to deliver on their promises due to low data quality. In the pharmaceutical industry, it entails an enormous economic burden.
- Organizations that treat data governance as a strategic priority gain a measurable advantage in translational efficiency and R&D productivity.
The promise of artificial intelligence to transform drug discovery is compelling. Yet, reality shows that most models fail. But they do not fail due to weak algorithms. They fail because the data feeding those algorithms was never designed for reuse, integration, or decision-making. The industry often conflates data abundance with data readiness – and that confusion is costly.
This article explores the critical distinction between merely ‘having data’ and possessing ‘usable data’ and how your data quality can impact the ability to leverage AI effectively in drug discovery and development.
The Hidden Cost of Poor Data
The pharmaceutical industry incurs significant financial and operational losses from training AI models on inadequately structured or biased data, thereby reducing productivity in research and development (R&D). The average cost of developing a new drug is estimated at $6.16 billion [1]. Preclinical research expenditures account for more than 43% of total costs in the pharmaceutical industry, driving these enormous expenses [2].
Huge losses are primarily due to the high attrition rate of projects that fail to deliver results. Even the most advanced algorithms become useless (sterile) if they are trained on benchmark data that is not adapted to the real problems of drug discovery. These models may perform well in retrospective tests but fail in real-world applications.
Another problem is the gap between biological causation and the correlation found by AI. AI is effective at revealing patterns, but without validation using biological samples and wet-lab experiments, it cannot master the complexities of human biology.
AI models trained on inadequately ingested and managed datasets poorly generalize to new, untested molecules. This can result in the rejection of valuable compounds. Commonly used medical chemistry filters have been shown to erroneously reject even FDA-approved drugs [3].
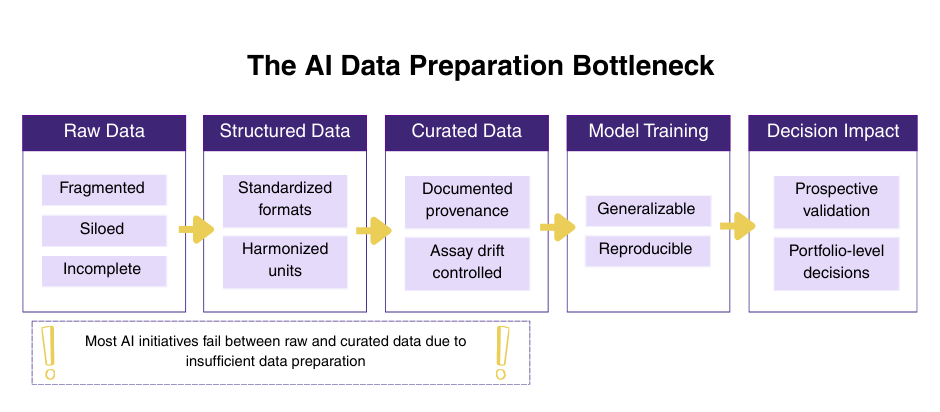
Figure 1: The AI data preparation bottleneck. Most organizations stall between Raw Data and Curated & Contextualized Data – the point where provenance, metadata, and assay consistency become non-negotiable.
Lessons Learned the Hard Way
Several high-profile AI-driven programs have highlighted the gap between promise and performance.
BenevolentAI’s lead candidate for atopic dermatitis (BEN-2293) failed in a Phase IIa trial, showing no greater efficacy than placebo in reducing inflammation and itching. This failure led to the termination of work on the drug, a sharp decline in share price (from €10 to less than €2 per share), and mass layoffs to reorganize the company [4].
Exscientia (recently acquired by Recursion) had to withdraw its phase I/II trial anti-cancer drug candidate (EXS-21546) after modeling showed difficulties in achieving an adequate therapeutic index [5]. Earlier, their partner, Sumitomo Pharma, abandoned another AI-designed drug for obsessive-compulsive disorder after disappointing trial results.
According to a recent MIT report, up to 95% of AI projects fail to deliver on their promises, primarily because the core issue is not the technology itself but the poor quality of the data used to train the models [6]. While enterprises invest billions in cloud infrastructure and foundation models, most struggle to operationalize AI because only a tiny fraction of their data is AI-ready.
Why Data Management Matters in Drug Discovery
Good data management ensures data is accessible, reliable, and trustworthy, fostering confidence in AI-driven outputs. This is crucial for making informed decisions at every stage of the drug discovery process, from target identification to clinical trial design, even without the use of AI.
Well-governed datasets also speed up manual scientists’ work, enabling them to integrate data from different sources and identify valuable insights faster.
This is especially important in multi-omics analysis, where integrating different data types can reveal complex relationships that would otherwise remain hidden.
In the absence of industry-wide data management standards, the burden of designing complex data systems has fallen directly on individual research centers. However, this challenge presents a unique opportunity: organizations that master structured data processes today will gain a decisive competitive advantage, ultimately enabling them to win the race to discover life-saving therapies.
Key Takeaways to Have in Mind Before AI Training
The question is not whether you have enough data. The question is whether your data passes the quality check. AI success in drug discovery begins long before the model selection and training. It begins with deliberate experimental design and well-governed datasets that align with downstream decisions.
Optimize Your Data Governance with Ardigen!
Author: Martyna Piotrowska
Technical editing: Ardigen expert: Ida Kupś
Bibliography
- Schuhmacher A, Hinder M, von Stegmann und Stein A, et al. Analysis of pharma R&D productivity – a new perspective needed. Drug Discov Today. 2023 28 (10); 103726. https://doi.org/10.1016/j.drudis.2023.103726
- Research and Development in the Pharmaceutical Industry. Congressional Budget Office [Internet]. [cited 2026 Feb 12]. [Available from:] https://www.cbo.gov/publication/57126
- Capuzzi SJ, Muratov EN, Tropsha A. Phantom PAINS: Problems with the utility of alerts for pan-assay interference compound. S J Chem Inf Model. 2017 (57): 417-427. https://pubs.acs.org/doi/10.1021/acs.jcim.6b00465
- Lowe D, AI and the hard stuff [Internet]. Science Blogs. 2023 May 25 [cited 2026 Feb 12].
- Dunn A, After years of hype, the first AI-designed drugs fall short in the clinic [Internet] Endpoint News. 2023 Oct 19 [cited 2026 Feb 12]. [Available from:] https://endpoints.news/first-ai-designed-drugs-fall-short-in-the-clinic-following-years-of-hype/
- State of AI in business 2025 [Internet]. MIT NANDA. 2025 [cited 2026 Feb 12]. [Available from:] mlq.ai/media/quarterly_decks/v0.1_State_of_AI_in_Business_2025_Report.pdf



