
For over half a century, the pharmaceutical industry has battled a paradox known as Eroom’s Law. While Moore’s Law predicts exponential growth in computing power, Eroom’s Law observes the opposite in drug discovery: the cost of developing new therapies has risen exponentially, and the tempo has slowed down.
Despite significant advances in artificial intelligence (AI), drug development continues to struggle [1]. Why does the situation remain stagnant and what we can do to change it? At the BioTechX USA 2025, during his insightful presentations, our expert Dawid explained how AI can finally reshape the economics of drug discovery and development.
Can AI Reverse Eroom’s Law Effect?
Can AI Reverse Eroom’s Law Effect?The cost of creating new treatments underwent a dramatic change in 2012, which coincided with the development of deep neural networks [2]. This may suggest a correlation, or even causality, between AI and a potential reversal of Eroom’s Law.
Despite early breakthroughs, widespread use of AI, for example, through tools such as ChatGPT, came much later, which explains why AI has not yet managed to halt the constant growth of drug development costs.
Data as the Key Driver
One of the most significant shifts in recent decades is the surge of biological data that can be used for AI models training. The cost of sequencing the human genome has plummeted – dropping even faster than expected. Similar advances in RNA sequencing, proteomics, metabolomics, and epigenomics have created an ocean of information waiting to be analyzed and harnessed.
At the same time, public resources such as the UK Biobank, TCGA and JUMP-CP have opened access to massive, high-quality datasets. These resources are fueling AI systems that can uncover hidden patterns in health and disease at a scale never seen before.
And here lies an actual paradigm shift: access to data is no longer the exclusive privilege of the largest pharmaceutical companies. With public biobanks and open repositories, even smaller players – such as start-ups, academic labs, or biotech innovators with smart ideas – can enter the game. The democratization of data means that the next breakthrough in drug discovery may just as well come from a nimble newcomer as from a global giant.
Case Studies: Ardigen’s Solutions for Successful AI Adoption in Life Sciences
While 95% of AI projects fail to deliver impact (according to an MIT report), well-designed strategies in life sciences are already showing results [3]. Several solutions crafted by our AI experts illustrate what successful adoption looks like.
1. Link Prediction Model in Biological Knowledge Graphs
A knowledge graph is a data structure used to store and organize extensive knowledge from many data sources. In other words, it is a large information repository in the form of a graph.
In biotechnology, the knowledge graph can be combined with disease maps, as well as internal AI models and other databases (e.g., FDA side effects or PubMed literature).
This case study aimed to use AI for link prediction (analyzing existing relations to infer new relations) in the biological knowledge graph. This is a classic example of the challenges and advantages of adopting AI in a scientific environment.
Initial problem:
The link prediction model in a large knowledge graph (comprising over 20 data sources) was inefficient, with training time exceeding 14 days, an inability to train on large datasets, and requiring 45 seconds per single prediction. The last parameter was critical because it was necessary to predict millions of associations simultaneously, and the performance was very poor.
The system was also inaccessible to biologists without coding skills, preventing them from gaining relevant or actionable insights for further analysis.
Ardigen’s solution:
To overcome these challenges, we employed a comprehensive strategy, leveraging infrastructure and new modeling approaches:
- To reduce the computational burden and inefficiencies, a cloud-based system (AWS)was designed, implemented and deployed.
- In order to optimize performance metrics, research was conducted on AI models and architectures suitable for this type of data. We also benchmarked and designed an appropriate validation scheme.
- To keep the system up to date and responsive to new information, a continuous training and inference loop was implemented, which updates models as new data becomes available.
- To enable biologists to grasp relevant discoveries from the system intuitively, a graphical user interface was provided.
Results:
The rebuilt system brought significant improvements, turning the initial failure into a success. The system became over 50 times faster. Training time was reduced by a factor of 20. The model was over 4 times more accurate than before.
Later, the system enabled our client to discover a novel target.
2. Patient Stratification in Complex Diseases: Leveraging Biobank Data
Complex diseases, especially in the neurodegenerative space, are challenging because we lack an in-depth understanding of the subtypes of these diseases and the relationships between them.
At the same time, public consortia provide massive cohorts of real-world data. This case study utilized patient data and their proteomic results from the UK Biobank.
Initial problem:
Applying conventional analytical methods to such large proteomic datasets raises issues. In the case of biobank data, these problems were:
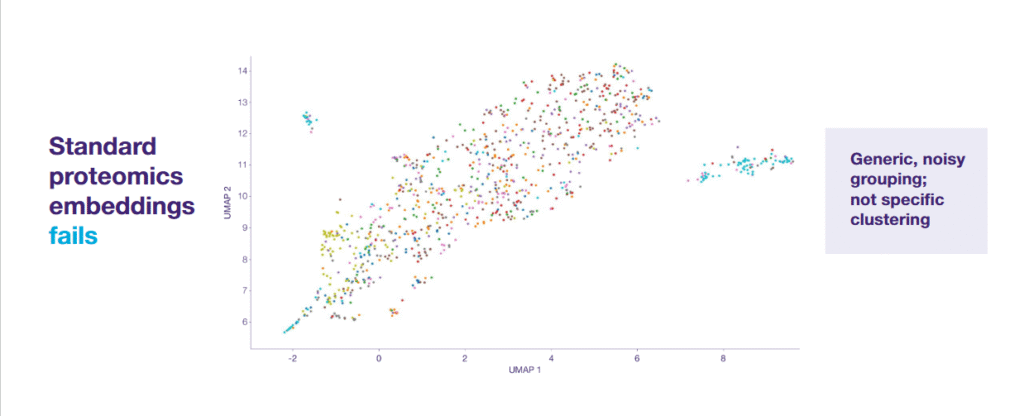
- Noisy representation, so standard methods of large-scale proteomics coding were not good enough.
- Lack of coherent clusters, meaning patients with similar diseases did not group.
- Lack of meaningful, actionable insights.
Ardigen’s solution:
The key to overcoming this challenge was the successful adoption of AI, based on data processing and curation to feed an advanced model.
At first, data ingestion, curation, and harmonization were performed to prepare the data for AI readiness. Then, we utilized a foundational model capable of predicting a patient’s disease status based on proteomic readings. The model built a representation of patients that could be further analyzed.
Results:
The model, trained on a large dataset, showed improved prediction in over 90% of tasks. Our approach transformed noisy data into practical scientific insights:
- The model effectively grouped patients into highly specific clusters based on disease subtypes.
- Use of explainability for artificial intelligence helped determine which proteins are responsible for these identified clusters.
- It was possible to identify biomarkers through retrospective analysis.
3. Large Language Models for Daily Productivity
Searching internal documentation has long been a bottleneck in pharma R&D. Large language models (LLMs) are changing this by enabling secure and efficient search across clinical reports, regulatory files, and scientific literature, saving valuable time and reducing redundancy.
Initial problem:
Although much of the adoption of AI in biotechnology focuses on highly complex scientific problems (e.g., target prediction, multi-omics analysis), successful AI implementation also applies to everyday work.
In the context of pharmaceutical companies and clinical trials, the significant challenge in document management is the difficulty in searching through all regulatory forms and finding analyses performed several years ago. These are often stored in PowerPoint or Excel files scattered in different data warehouses.
Ardigen’s solution:
In response to this challenge, we propose to construct an internal system based on large language models (LLMs).
The system integrates information from various storage sources (e.g., Box, Google Drive) and communication systems (Microsoft Teams, Google Chat), emails and PDF files. All this data is encoded and placed in an internal document manager, which is then connected to large language models such as ChatGPT.
A designed internal system can also seamlessly combine internal data with findings from scientific literature, summarizing publications from PubMed.
A simple interface, similar to ChatGPT, allows the end user to easily enter a query and retrieve the desired information.
Results:
Adopting this LLM-based system brings measurable benefits by increasing operational efficiency:
- Very simple systems, such as LLM-based search engines, can significantly increase productivity and speed up daily work.
- A key advantage is that users can search all these documents, including confidential information, clinical documents, and regulatory forms, without the risk of information leaking into the public domain. The entire process takes place in the organization’s closed cloud.
- It allows users without coding skills to intuitively interact with the data and tools that have been provided.
4. Drug Repurposing With Agentic AI
Repurposing existing drugs can be faster and less risky than developing new ones, but the process is time-consuming. Agent-based AI systems now aggregate information from knowledge graphs, PubMed, and FDA safety data, then generate hypotheses supported by evidence. What once took months can now be done in weeks.
Initial problem:
Before the application of agent-based AI, the drug repurposing process was time-consuming and prone to error. Repurposing programs rely on numerous hypotheses and require the analysis of many data sources.
Manually summarizing and evaluating results from different sources to determine their relevance or scientific validity could take weeks. Moreover, performing such analysis manually increases the risk of omitting details or generating incorrect reports.
Ardigen’s solution:
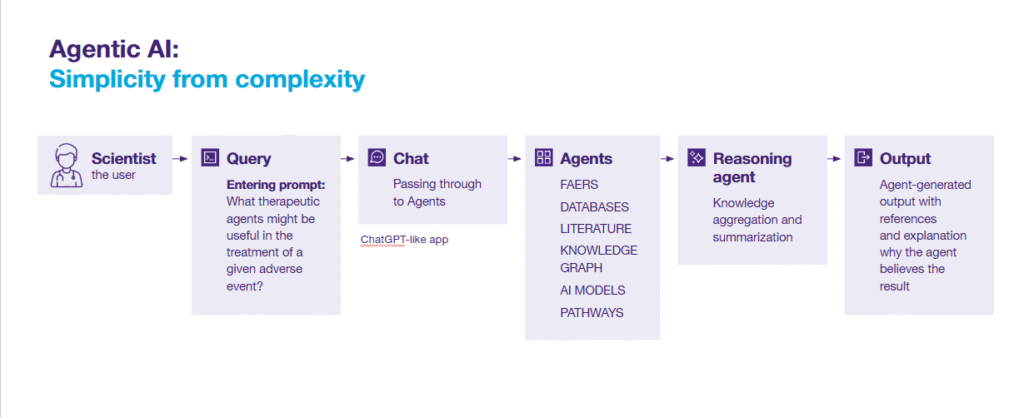
We used agentic AI as a solution that automates and optimizes the process of generating and validating repurposing hypotheses.
We designed an agent to combine and utilize all the information and databases to which it has access. These resources include:
- Knowledge graphs containing disease maps.
- Scientific literature data from PubMed.
- Internal AI models that predict the properties of specific targets.
- Information on biological pathways and adverse effects from the FDA.
The second reasoning agent collects all this information and finally summarizes it.
Results:
Instead of scattered findings, researchers receive a complex and comprehensive report that directly points to the evidence supporting a given repurposing hypothesis.
Agent AI significantly reduces the time required to evaluate hypotheses from weeks to a much shorter timeframe, thereby increasing program throughput. Furthermore, it minimizes the risk of human error and omissions by generating a comprehensive report based on integrated evidence.
The system has been designed to be extendable. As the organization grows, new agents can be introduced and integrated to support new modalities or resources.
Why Adoption Matters
These examples highlight a crucial point: AI adoption is not about replacing scientists but about empowering them. Success depends on two factors:
- Data readiness – reliable, well-curated datasets that reflect the problem at hand.
- Accessible tools – interfaces that allow biologists and clinicians to use AI insights without needing advanced coding skills.
When those conditions are met, AI improves efficiency and frees experts to focus on creative problem-solving and discovery. Credibility that builds trust and simplification of AI use encourage people to use these solutions daily and incorporate them into workflows for longer.
From Insight to Patient Impact
The stakes are high. Each year, the FDA approves ~50 new drugs, with only about 5% of programs reaching this finish line. Even a 1% increase in success rates, made possible by AI-driven insights, could result in the addition of 10 new therapies annually. For patients, that means more options, faster.
Ardigen is a company specializing in data and AI-based solutions for drug discovery, biotechnology, life science and pharmaceutical companies. We built for our clients’ infrastructure (data organization, visualization, data modality integration) and help gain scientific insights faster (discovery and target prioritization, indication expansion, chemoinformatics, phenotypic screening, biological drugs, knowledge extraction, biomarkers and stratification).
Scientific discoveries and research drive Ardigen to develop solutions tailored to specific problems. We have already worked on over 500 projects with more than 100 partners, spanning 10 years on the market.
Want to join the trend? Consult our experts to learn how to effectively implement AI solutions within your organization.
Author: Martyna Piotrowska |
Technical editing: Ardigen expert: Dawid Rymarczyk, PhD
Bibliography:
- OECD, Artificial Intelligence in science: challenges, opportunities and the future of research. 2023. OECD Publishing Paris, https://doi.org/10.1787/a8d820bd-en
- Scannell, Jack W., et al. Diagnosing the decline in pharmaceutical R&D efficiency. Nat Rev Drug Disc. 2012. 11 (3): 191-200, https://doi.org/10.1038/nrd3681
- Challapally A, Pease C, Raskar R, Chari P. The genAI divide. State of AI in business 2025. 2025. Jul: 1–25. Available from: https://mlq.ai/media/quarterly_decks/v0.1_State_of_AI_in_Business_2025_Report.pdf



