
Data Privacy in Biotech AI: Why Privacy Is Now a Technical Constraint
Summary: Data privacy in biotech AI has become a system-level technical constraint that shapes how AI models are designed, deployed, and scaled across discovery and translational research. Biological data such as genomics, imaging, and phenotypic profiles carry persistent identifiers that limit anonymization and shift privacy risk from datasets into trained models and downstream reuse. Multimodal AI further amplifies this risk through cross-modal correlations, while large-scale data sharing via biobanks remains essential for scientific progress. In response, regulatory frameworks increasingly emphasize lifecycle-based governance, making privacy-aware architecture a core requirement for scalable AI in biotech and pharma.
In biotechnology and pharmaceutical R&D, data privacy has evolved into a system-level concern that directly influences how AI-driven research is designed and scaled. As artificial intelligence becomes embedded in discovery, preclinical research, and translational workflows, privacy considerations increasingly shape data architectures, model development, and operational practices. These constraints emerge not only at the level of datasets, but also within models, pipelines, and their reuse across programs.
For teams working with biological data, this shift has practical implications. Choices around data access, integration, and governance affect scientific validity, regulatory readiness, and long-term reusability of AI systems. Data Privacy Day provides an opportunity to examine privacy not as a legal afterthought, but as a technical dimension of modern biotech infrastructure.
Why biotech data presents unique privacy challenges
Biological data differs fundamentally from many other data types used in AI. Genomic data, in particular, carries persistent identifiers that remain linkable even after direct personal identifiers are removed. Under the GDPR framework, genetic and health data are classified as special category data, reflecting their inherent sensitivity and re-identification risk [1]. Regulatory guidance and public research policy acknowledge that effective anonymization of such data is difficult to achieve without undermining scientific and research utility [5]. This creates a narrow trade-off between privacy protection and scientific usability.
High-content imaging and phenotypic profiling pose related challenges. Cellular morphology, spatial organization, and longitudinal response patterns can function as indirect identifiers, especially when combined with experimental metadata. When datasets from different studies or modalities are integrated, identifiability can re-emerge even if individual datasets were originally considered de-identified.
Longitudinal datasets and small cohorts further increase exposure. In rare disease research or early-stage discovery programs, limited cohort sizes amplify the risk of re-identification through linkage. These characteristics place biotech data at the intersection of privacy protection, intellectual property concerns, and the need for scientific reproducibility.
How AI amplifies privacy risk in practice
AI systems reshape privacy risk by learning and internalizing statistical structure from data rather than simply storing or querying records. This shifts privacy considerations beyond traditional access control models toward risks associated with how models are trained, reused, and deployed. Cybersecurity authorities increasingly frame AI-related privacy exposure as a system-level issue that spans data, models, and downstream use rather than a single point of failure [2].
Importantly, these risks do not depend on direct access to raw data. Guidance from data protection authorities highlights that trained models themselves may act as carriers of sensitive information if reused, shared, or deployed without appropriate governance. AI systems can enable inference of sensitive attributes even when direct identifiers are absent, particularly in high-dimensional biological and clinical data [3]. In this context, privacy risk migrates from datasets into model artifacts, outputs, and downstream use.
In practice, this risk increasingly materializes through everyday use of general-purpose AI tools. Pasting molecular structures, patient-level data, or clinical trial results into externally hosted generative AI models can unintentionally expose sensitive information beyond organizational control. Similar concerns apply to productivity tools with embedded AI capabilities, such as AI copilots, where sensitive biological or clinical data may be processed outside validated research environments. Importantly, data entered into AI systems under a GDPR consent basis may not be practically deletable once incorporated into a trained model, creating long-term compliance and governance challenges.
Multimodal AI further amplifies this effect. When genomics, imaging, and experimental or clinical metadata are combined, cross-modal correlations may surface biological or individual-level information that is not evident within any single data source. From a regulatory perspective, this increases the importance of documenting context of use, data provenance, and interactions across the AI lifecycle. Recent regulatory frameworks emphasize lifecycle-based risk management and transparency obligations precisely to address these cumulative and emergent risks [4].
Why anonymization alone is rarely sufficient
Anonymization has traditionally been treated as a primary privacy safeguard. In biological research, its limitations are increasingly well documented. Genomic data resists irreversible anonymization by design, and public research agencies acknowledge that even coded or aggregated genomic datasets may remain re-identifiable when combined with external information [5].
From a technical perspective, aggressive anonymization often conflicts with scientific traceability. Removing metadata, perturbation context, or longitudinal links may reduce privacy exposure but also undermines reproducibility and validation. In AI workflows, this tension becomes particularly visible: models rely on consistent biological and experimental context to generalize, while anonymization techniques tend to fragment that context.
As a result, many biotech AI pipelines rely on pseudonymization rather than anonymization, combined with strict access control and governance. Under GDPR, pseudonymized data remains personal data, but it enables controlled scientific use while preserving auditability and traceability [1].
Data sharing remains essential for science
Despite these challenges, broad data restriction is not a viable strategy for drug discovery. Scientific progress in biotech relies on data sharing across sites, partners, and studies. External validation, multicenter research, and regulatory review all require controlled reuse of data and models.
Large-scale shared resources illustrate this clearly. Biobanks and population-level datasets enable longitudinal analysis, cross-cohort validation, and the development of more generalizable AI models. Public and semi-public datasets also play a central role in benchmarking methods and supporting reproducibility across the industry.
Regulatory agencies implicitly recognize the necessity of data sharing. Both the FDA and the EMA emphasize traceability and credibility of data used to support scientific and regulatory decisions, assuming that data and models can be examined, reproduced, and contextualized rather than isolated [6][7].
Privacy risk as a system-level property
In practice, privacy risk in biotech AI rarely arises from a single failure point. Instead, it emerges across the lifecycle of data and models, shaped by how biological data is collected, integrated, reused, and operationalized. Security agencies increasingly describe privacy as an emergent system property rather than a static attribute of individual datasets [2].
Re-identification risk remains one of the most persistent concerns, particularly for genomic and imaging data. Model-related risks introduce a second layer, where trained systems may encode sensitive patterns that persist beyond the original training context. Longitudinal reuse of data and models adds a temporal dimension, creating the potential for privacy drift as systems are repurposed beyond their original governance assumptions.
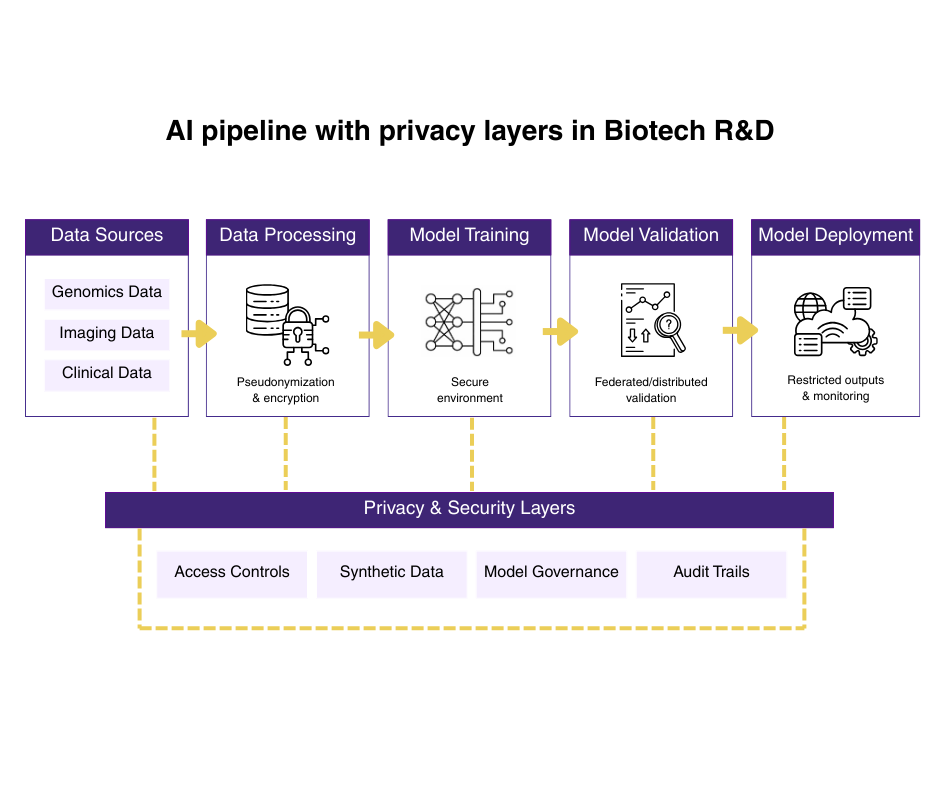
Fig 1 AI pipeline with privacy layers
The table below summarizes common privacy risk areas in biotech AI systems and the technical strategies typically used to mitigate them. Importantly, these strategies are most effective when aligned with where risk arises in the system, rather than applied uniformly.
Risk area | Where it appears | Why it matters | Technical mitigation |
|---|---|---|---|
Re-identification | Genomics, imaging | Persistent biological identifiers | Pseudonymization, access control |
Model leakage | Trained AI models | Sensitive patterns encoded | Output controls, model governance |
Cross-study linkage | Longitudinal datasets | Hidden identity inference | Context separation, minimization |
Cross-border processing | Cloud pipelines | Regulatory exposure | Regional processing, SCCs |
Uncontrolled reuse | Pretrained models | Privacy drift over time | Documentation, versioning, audits |
Table 1. Privacy risks and technical mitigation strategies in biotech AI
Technical strategies that support privacy at scale
Effective privacy protection in biotech AI depends on architectural and organizational decisions rather than isolated safeguards. In practice, many biotech and pharmaceutical teams establish in-house data protection or privacy offices that provide concrete guidance on anonymization, pseudonymization, and acceptable data use in AI workflows. Maintaining detailed GDPR compliance records – including which datasets are pseudonymized, which safeguards are applied, and which data may be shared externally – supports both regulatory readiness and internal clarity.
On the technical side, organizations increasingly deploy safeguards that monitor and restrict AI access to sensitive data. These include automated scanning for regulated data, controls that prevent unauthorized use of external AI services, and clearly separated internal or private model environments. However, technology alone is insufficient. Regular employee training in AI safety and data handling practices plays a critical role in reducing inadvertent data exposure and ensuring that privacy-aware behavior scales alongside AI adoption.
Industry data suggests that gaps between AI adoption and data protection readiness remain significant. A recent Contract Pharma analysis reports that while pharmaceutical companies rapidly adopt AI-driven tools, a large majority lack comprehensive AI-specific data security and compliance measures, exposing sensitive research and clinical data to avoidable risk [8].
Regulatory signals engineers should pay attention to
Recent regulatory developments reinforce the technical nature of privacy obligations. GDPR remains the foundation for personal data protection in Europe. The EU AI Act adds system-level requirements for risk management, transparency, and governance, with staged obligations applying from 2025 onward [4].
In parallel, FDA and EMA guidance emphasizes that data and AI systems used in regulated contexts must be traceable and credible. Compliance increasingly depends on how systems are built and operated, rather than how they are described in documentation [6][7].
What this means for biotech and pharma teams in 2026
For technical teams, privacy expertise can no longer sit exclusively within legal or compliance functions. Data engineers, bioinformaticians, and ML practitioners directly shape privacy outcomes through architectural choices. Addressing privacy constraints early—before model training and system integration—improves scalability and reduces downstream friction.
Organizations that align data strategy, AI development, and regulatory understanding are better positioned to move beyond pilot projects. Teams that treat privacy as an afterthought often build systems that struggle to scale, regardless of model performance.
Ardigen’s perspective
Across projects, data privacy consistently emerges as a core component of data maturity. Scalable AI in biotech depends on trustworthy data pipelines, clear governance, and technical transparency. When privacy is designed into systems from the outset, it supports collaboration, reproducibility, and long-term value creation.
Bibliography
[1] European Data Protection Board (EDPB) – Guidelines on the processing of data concerning health for scientific research purposes (Guidelines 03/2020) and the general framework for special categories of personal data under GDPR (Article 9). https://www.edpb.europa.eu/our-work-tools/our-documents/guidelines/guidelines-032020-processing-data-concerning-health-purpose_en
[2] ENISA. Threat Landscape for Artificial Intelligence.
https://futurium.ec.europa.eu/fi/european-ai-alliance/community-content/enisa-ai-cybersecurity-challenges-threat-landscape-artificial-intelligence[3] UK Information Commissioner’s Office (ICO). Guidance on AI and data protection.
https://ico.org.uk/for-organisations/uk-gdpr-guidance-and-resources/artificial-intelligence/guidance-on-ai-and-data-protection/[4] European Commission. EU Artificial Intelligence Act.
https://digital-strategy.ec.europa.eu/en/policies/regulatory-framework-ai[5] National Institutes of Health (NIH). Genomic Data Sharing Policy.
https://sharing.nih.gov[6] U.S. Food and Drug Administration (FDA). Considerations for the Use of Artificial Intelligence to Support Regulatory Decision-Making for Drug and Biological Products (Draft Guidance).
https://www.fda.gov/regulatory-information/search-fda-guidance-documents/considerations-use-artificial-intelligence-support-regulatory-decision-making-drug-and-biological[7] European Medicines Agency (EMA). Reflection paper on the use of artificial intelligence in the medicinal product lifecycle.
https://www.ema.europa.eu/en/documents/scientific-guideline/reflection-paper-use-artificial-intelligence-ai-medicinal-product-lifecycle_en.pdf[8] Contract Pharma. AI & Data Security: The 83% Compliance Gap Facing Pharmaceutical Companies. https://www.contractpharma.com/exclusives/ai-data-security-the-83-compliance-gap-facing-pharmaceutical-companies/



