
Biomarkers are the biological signatures that drive precision medicine. They help us predict disease risk, monitor progression, evaluate treatment response, and match patients with the most effective therapies. However, their discovery and validation need a technology boost to raise the success rates.
From gene mutations to altered protein expression profiles and metabolic fingerprints, biomarkers are signatures of the disease. They can then be used for disease diagnosis, prognosis, or monitoring, especially in oncology targeted therapies depend on accurate, timely molecular information.
However, identifying high-quality biomarkers remains one of the most pressing challenges in biomedical research.
Although the MarkerDB 2.0 database contains 27128 clinically approved biomarkers, the truth is that only a handful of biomarker candidates are successfully validated for clinical use. Why? The process is highly selective due to strict requirements for analytical validity, clinical utility, and regulatory acceptance. In the U.S., there are three main pathways to qualify a biomarker:
- scientific community consensus (used to support hypotheses),
- co-development with a new drug application, a
- nd formal review through the FDA’s Biomarker Qualification Program.
Traditional approaches struggle with the complexity of biological systems. Single-omic strategies often miss the bigger picture: the multilayered interplay between genes, transcripts, proteins, and metabolites that shape all disease mechanisms.
To accelerate and improve biomarker discovery, scientists turn to omic data integration. A shift that’s redefining how we identify, validate, and translate knowledge on clinical biomarkers into effective therapies delivered to the right patients.
The data has been gathered already
Omic datasets are no longer the bottleneck. Many organizations possess vast collections of omic data generated internally or through collaborations and clinical trials.
Even more data is openly available.
Public initiatives like The Cancer Genome Atlas (TCGA) and DepMap – the Cancer Dependency Map from the Broad Institute have made multi-omic datasets accessible at an unprecedented scale. TCGA offers comprehensive profiles of more than 10,000 tumors across 33 cancer types, while DepMap integrates large-scale gene inactivation screens with genomic, transcriptomic, proteomic, and pharmacologic characterizations of human cancer cell lines.
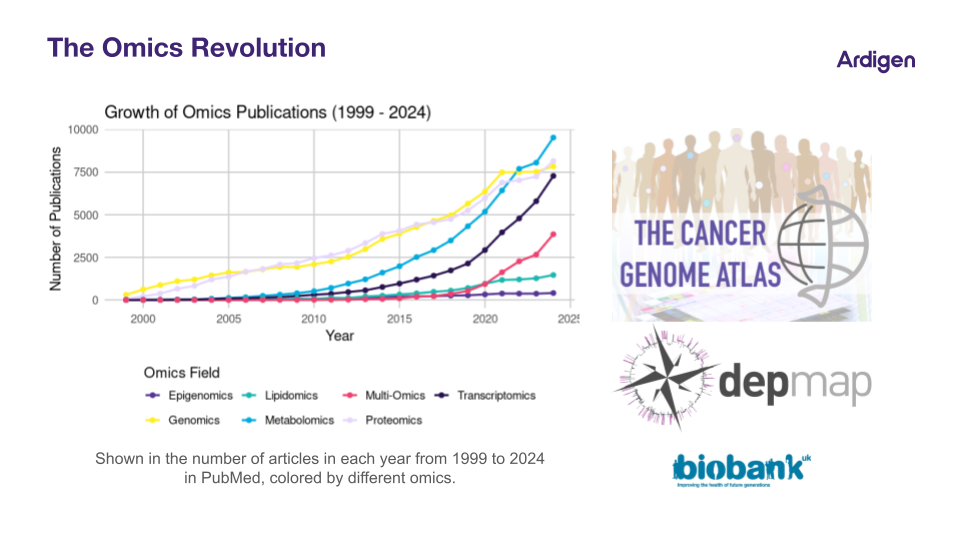
These resources now fuel machine learning models that link molecular features to drug response, opening new possibilities in biomarker discovery.
But data alone isn’t enough. Now it’s time to make them work.
From "One Biomarker, One Outcome" to a systems biology approach
Early discovery efforts often relied on univariate analysis – looking at one feature at a time, integrating different omic layers. While this approach helps identify strong, independent predictors, it rarely captures the complexity of disease biology.
Multivariate methods allow the detection of networks, dependencies, and emergent properties that are invisible in single-layer analyses. They provide a more realistic model of biological systems, especially in areas like tumor heterogeneity and drug resistance.
Dong et al., in an extensive bibliometric analysis published in Human Vaccines and Immunotherapeutics in 2025, highlight a rapid growth in omics-driven tumor immunotherapy research since 2019, showcasing an increasing interest and investment in this field.
The study indicates 9,494 publications on omics in tumor immunotherapy, a substantial body of research in this area. The trends will grow constantly, as about 2000 papers were published yearly during the last two years.
They demonstrate that omics technologies drove significant advancements in tumor immunotherapy, and multi-omics integration will emerge as a central focus in cancer research. Thus, integrating spatial omics and AI-driven models holds great promise for translating omics data into clinical practice.
The promise (and pitfalls) of multi-omics
Still, multi-omics integration brings challenges, including data heterogeneity, statistical noise, and reproducibility issues. Integrating high-dimensional datasets without proper prior harmonization can lead to misleading conclusions or analytical barriers without the right tools and frameworks.
This is where complex data-driven approaches overcome these challenges, including:
- Real-world examples of data-driven biomarker strategies.
- The role of univariate vs. multivariate analysis in clinical validation.
- Integration tools that support translational research.
Why this matters for biotech and pharma
According to Grand View Research, the global biomarkers market is expected to reach USD 194.21 billion by 2030, driven by increasing demand for personalized therapies, clinical biomarkers in early-phase trials, and AI-based biomarkers discovery solutions.
The next generation of biomarkers demands understanding the full biological context through omic data integration, systems-level modeling, and AI-enhanced discovery. If you’re ready to learn what’s possible when we fill the data-to-therapy gap, don’t miss the upcoming Ardigen’s webinar.
The meeting will explore these strategies in depth, showing how multi-omic data synthesis:
- Identify robust predictive and prognostic biomarkers.
- Use them for patient stratification to assess their potential in clinical trials.
- Support drug discovery pipelines.
- Assign targeted therapies to patients.
Expert Contribution
Multi-omics integration and data harmonization are a core focus of our team. Krzysztof Kolmus, PhD, a Senior Bioinformatician at Ardigen, brings extensive expertise in NGS data analysis and cloud-based workflows to solve these issues. His work ensures our data-driven approaches overcome pitfalls like data heterogeneity and statistical noise.




